Imagine you’re trying to teach a child to recognize animals. You show them a few pictures and clearly say, “This is a dog,” “This is a cat,” “This is a horse.” But then you also hand them a big stack of unlabeled pictures and let them explore on their own. Over time, they begin to spot patterns—fur, tails, ears—and get better at guessing even when you haven’t labeled every image.
That’s essentially how semi-supervised learning works in artificial intelligence.
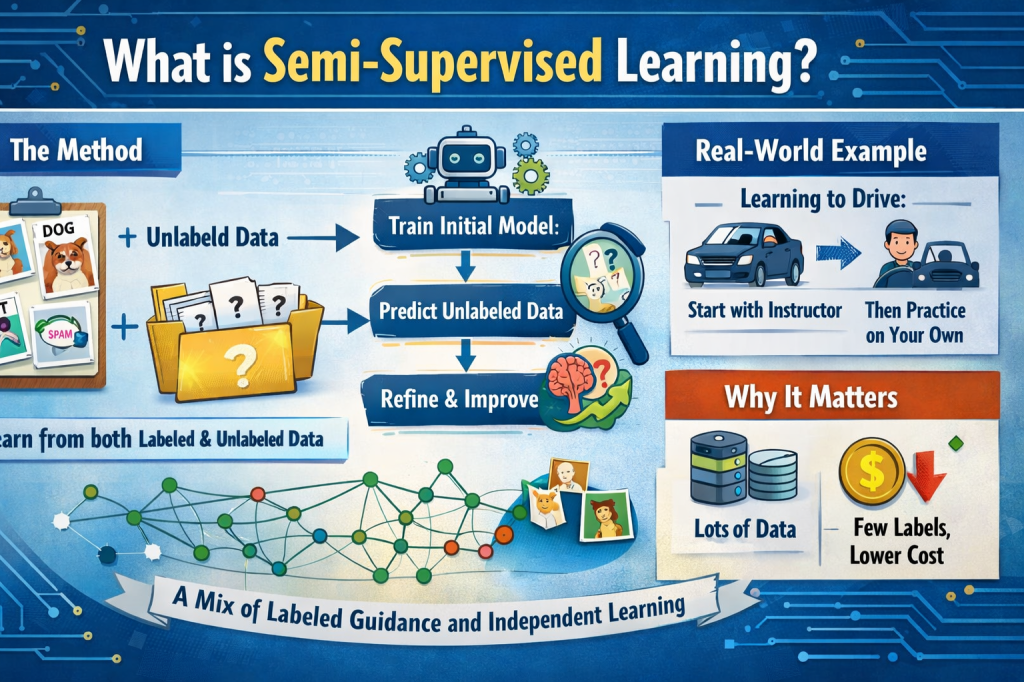
Semi-supervised learning is a machine learning approach that uses a small amount of labeled data and a large amount of unlabeled data to train models. It sits right between supervised learning (where all data is labeled) and unsupervised learning (where nothing is labeled).
Let’s break that down in plain English.
The Problem with Labels
In supervised learning, every piece of data must be labeled. For example:
- Emails marked as “spam” or “not spam”
- X-rays labeled “healthy” or “fracture”
- Photos labeled “cat,” “dog,” or “car”
The challenge? Labeling data takes time, money, and human effort. If you’ve ever tagged photos or sorted emails manually, you know how tedious it can be.
Now imagine you’re building a medical AI system. Getting 1,000 X-rays labeled by expert doctors could cost a fortune. But you might have access to 100,000 unlabeled X-rays sitting in a hospital database.
Semi-supervised learning says:
“Why waste all that unlabeled data?”
How Semi-Supervised Learning Works
Here’s the core idea:
- Start with a small labeled dataset.
- Train an initial model.
- Use that model to make predictions on unlabeled data.
- Use confident predictions to improve the model further.
It’s a bit like learning with a tutor for a few sessions, then practicing on your own with some guidance.
For example, suppose you’re building a spam detection system:
- You label 500 emails manually.
- You train a model on those 500.
- The model analyzes 50,000 unlabeled emails and identifies patterns.
- It becomes better at distinguishing spam from non-spam—even without explicit labels for all emails.
The unlabeled data helps the model understand the overall structure of the data—like noticing clusters or patterns that labeled examples alone might miss.
A Real-World Analogy
Think of learning to drive.
At first, an instructor gives you clear instructions: “Press the brake gently,” “Check mirrors before turning.” That’s your labeled data.
After a few lessons, you drive more independently. You encounter new roads, traffic conditions, and weather situations. Even without constant instruction, you improve by recognizing patterns and gaining experience.
That’s semi-supervised learning in action: a mix of guided instruction and independent pattern discovery.
Why It Matters
Semi-supervised learning is powerful because:
- Data is abundant, labels are scarce.
We generate massive amounts of data every day—photos, videos, texts—but very little of it is labeled. - It reduces cost.
You don’t need to label everything. - It improves performance.
Models can generalize better by understanding broader data patterns.
This approach is widely used in areas like:
- Medical image analysis
- Speech recognition
- Fraud detection
- Natural language processing
In many cases, it performs almost as well as fully supervised learning—but with far fewer labeled examples.
The Key Idea: Structure in Data
Here’s the deeper insight.
Semi-supervised learning assumes that data has an underlying structure. For example:
- Similar items tend to group together.
- Data points close to each other are likely to share the same label.
Imagine plotting customer data on a graph. You might see clusters forming naturally. Even if only a few points are labeled “high spender,” the model can guess that nearby unlabeled points may belong to the same category.
It’s like walking into a party where you know only two people. If you see them standing in a group laughing, you might assume others in that circle share similar interests.
When Should You Use It?
Semi-supervised learning is especially useful when:
- You have a lot of raw data.
- Labeling is expensive or slow.
- You need better performance than unsupervised learning can provide.
However, it’s not magic. If your labeled data is poor quality, or your assumptions about data structure are wrong, the model can make confident but incorrect predictions.
So, careful design still matters.
Key Takeaways
Semi-supervised learning blends the best of both worlds: the clarity of labeled data and the abundance of unlabeled data. It’s practical, cost-effective, and increasingly important in today’s data-rich world.
If supervised learning is like studying with a textbook and unsupervised learning is like exploring without guidance, semi-supervised learning is like having a mentor for the basics and then learning from real-world experience.
As AI systems continue to grow, this approach helps bridge the gap between limited human labeling and unlimited machine learning potential.
If you’re exploring machine learning, understanding semi-supervised learning gives you a powerful tool for building smarter systems without breaking the bank.
Check out my collection of e-books for deeper insights into these topics: Shafaat Ali on Apple Books.

Leave a comment